写在前面
说到人工智能(AI),你可能会想到ChatGPT、自动驾驶、人脸识别……但如果让你给AI下个定义,是不是突然觉得"只可意会不可言传"?别急,今天我们就来系统性地拆解一下AI的核心概念,用人话把这些听起来高大上的术语讲明白。
读完这篇文章,你会理解:
- AI、机器学习、深度学习到底是什么关系
- 机器是怎么"学习"的
- 为什么有时候模型会"过于聪明"或"不够聪明"
- 训练模型的底层逻辑是什么
什么是人工智能?
在我看来,人工智能就是让机器具备同时获得、建立、发展和运用知识的能力。注意这里的关键词——不只是"存储"知识,而是要能"建立"和"运用"。
你可能会说:"这不就是让电脑变聪明嘛!"没错,但这个"聪明"可不简单。AI不是单纯的if-else逻辑判断,而是要让机器能够从数据中学习规律,并在新情况下做出合理的决策。
AI、ML、DL的关系
很多人分不清AI、机器学习(ML)、深度学习(DL)的区别。其实用一张经典的同心圆图就能说明白:
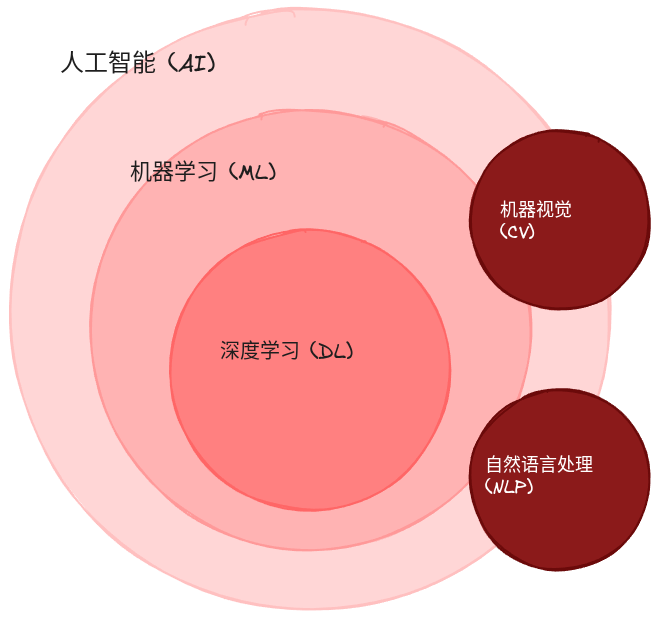
简单来说:
- AI是目标 - 我们想让机器变聪明
- 机器学习是方法 - 通过算法让机器从数据中学习
- 深度学习是工具 - 用深层神经网络这种特殊的机器学习方法
机器学习的三大派系
机器学习按照学习方式的不同,可以分为三大类:监督学习、无监督学习和强化学习。
监督学习:手把手教
监督学习就像是家长教小孩认字——你指着苹果的图片说"这是苹果",指着香蕉说"这是香蕉",反复教多了,孩子就记住了。
在监督学习中,数据集中的每条数据都带有标签。比如:
- 图片分类:每张水果图片都标注了是什么水果
- 垃圾邮件检测:每封邮件都标记了是否为垃圾邮件
- 房价预测:每套房子都有对应的实际成交价
# 监督学习示例:水果分类
训练数据 = [
(苹果图片, 标签="苹果"),
(香蕉图片, 标签="香蕉"),
(葡萄图片, 标签="葡萄"),
...
]无监督学习:自己找规律
无监督学习就像是让孩子自己整理玩具——没人告诉他怎么分类,但他可能会把车子归一堆、把积木归一堆,自己发现物品之间的相似性。
在无监督学习中,数据是没有标签的,机器需要自己发现数据中的模式和结构。典型应用:
- 用户分群:根据用户行为自动划分用户类型
- 异常检测:找出数据中的异常值
- 推荐系统:发现用户的潜在兴趣
强化学习:试错中成长
强化学习就像训练狗狗——做对了给零食(奖励),做错了不给(惩罚),狗狗就会逐渐学会什么行为能获得奖励。
强化学习有三个核心要素:
- 智能体(Agent):执行动作的主体,比如游戏中的AI玩家
- 环境(Environment):智能体所处的世界
- 行为(Action):智能体可以执行的操作
经典案例就是AlphaGo下围棋:赢了就奖励,输了就惩罚,通过不断对弈,AI逐渐学会了下围棋的策略。
半监督学习与自监督学习
现实中还有两种特殊的学习方式:
半监督学习 - 有些数据有标签,有些没有。就像班上有几个学霸(已标注数据)带着其他同学(未标注数据)一起学习。互联网时代数据爆炸,人工标注成本太高,半监督学习应运而生。
自监督学习 - 这是近年来的热门方向,监督信息不是人工标注的,而是算法自己构造的。
举个例子:BERT这个自然语言处理模型的训练过程:
- 挖空填词:把句子中的某些词遮住,让模型猜
- 句子顺序判断:给两个句子,让模型判断第二句是否承接第一句
这些"题目"都是算法自动生成的,不需要人工标注,这就是自监督学习的魅力。
深度学习:神经网络的黑魔法
深度学习基于深度神经网络,是监督学习的一种。但现代深度学习模型通常会结合多种学习方式,比如语言模型预训练就属于自监督学习。
为什么叫"深度"?
因为神经网络的层数堆得很深,少则几十层,多则上百层。这种多层结构能够学习到数据的多层次抽象特征。
为什么说它是"黑盒"?
目前深度学习没有严谨的数学证明来解释为什么神经网络有效,不像传统的SVM(支持向量机)等算法有严格的数学理论支撑。
所以深度学习从业者常常自嘲是在**"炼丹"**:
- 准备原材料(数据)
- 调配丹方(模型架构)
- 控制火候(超参数)
- 看结果如何(丹成还是炸炉)
这个过程充满了试错和经验,很像古代炼丹师的工作😄
AI是怎么训练的?
理解了学习方式,下面我们来看看AI训练的完整流程。
训练的四大步骤
1. 数据收集与预处理
↓
2. 模型构建
↓
3. 定义损失函数和优化方法
↓
4. 训练、检验与优化数据为王
业内有句话:数据为王。谁的数据量越大、数据质量越高,谁就能拥有最"智能"的AI。
这就是为什么互联网巨头在AI领域有天然优势——他们手握海量的用户数据。
损失函数:量化"错得有多离谱"
AI的"学习"本质上是模型参数的不断更新。那模型怎么知道自己预测得对不对呢?答案是损失函数(Loss Function)。
损失函数就是用来衡量预测值和实际值之间差距的函数。
举个例子:训练一个水果分类模型:
- 数据准备:把标签转换成数字(1=苹果,2=香蕉,3=葡萄...)
- 模型预测:输入一张苹果图片,模型输出预测值=2(香蕉)
- 计算损失:实际值=1(苹果),预测值=2,有误差!
- 损失函数量化这个误差,比如 Loss = |1-2| = 1
不同任务使用不同的损失函数:
- 分类任务:交叉熵损失(Cross Entropy Loss)
- 回归任务:均方误差(MSE, Mean Squared Error)
- 图像生成:对抗损失(Adversarial Loss)
梯度下降:下山找最优解
有了损失函数,我们的目标就是最小化损失。常用的优化方法叫梯度下降(Gradient Descent)。
梯度下降可以类比成下山的过程:
想象你被困在山上,需要下到山谷(最低点)。但浓雾弥漫,能见度很低,你看不清下山的路。这时候,你可以采用这样的策略:
- 看看周围哪个方向最陡(梯度最大)
- 朝着下坡的方向走一段距离(学习率)
- 到达新位置后,重复步骤1-2
- 最终到达山谷(损失函数最小值)
# 梯度下降的伪代码
当前位置 = 初始参数
while 没有到达山谷:
梯度 = 计算当前位置的坡度
步长 = 学习率
当前位置 = 当前位置 - 步长 * 梯度在这个过程中,模型参数会不断更新,直到找到一个损失函数较小的参数组合。
局部最优 vs 全局最优
理想很丰满,现实很骨感。山上可能有多个"山谷"(局部最优点),你可能到达的只是一个小山谷而不是最低的大山谷(全局最优点)。
但好消息是:实践中,找到的局部最优点通常已经足够好了,不一定非要找到全局最优。
过拟合与欠拟合:平衡的艺术
训练模型时,我们通常会把数据集按8:2的比例分成训练集和测试集。
- 训练集:用来训练模型
- 测试集:用来评估模型的泛化能力(模型没见过这些数据)
训练过程中会遇到三种情况:
欠拟合:学艺不精
欠拟合就是模型学得不够,太简单了,连训练集都拟合不好。
表现:
- 训练集上效果差 ❌
- 测试集上效果差 ❌
解决方法:
- 引入更多特征
- 使用更复杂的模型
- 增加训练时间
类比:让小学生做高考题——基础不够,怎么努力都做不好。
过拟合:死记硬背
过拟合是另一个极端,模型在训练集上学得太好,但太死板,不会变通。
表现:
- 训练集上效果很好 ✅
- 测试集上效果差 ❌
举个例子:训练一个手写字识别模型。过拟合的表现就是:
- 看到和训练集中一模一样的字迹,能正确识别
- 看到不同的字迹、不端正的写法,就识别不出来了
这就像是背答案的学生——题目稍微变一变就不会了。
解决方法:
- 扩大训练数据集
- 降低模型复杂度
- 加入正则化(Regularization)
- 在合适的时候提前停止训练(Early Stopping)
理想状态:恰到好处
理想的模型应该:
- 训练集上效果好 ✅
- 测试集上效果也好 ✅
这就是我们追求的泛化能力——不仅能学会训练数据,还能处理没见过的新数据。
欠拟合 理想状态 过拟合
(Underfitted) (Good Fit) (Overfitted)
• • • •
• • • • • •
• • • • •
—————— ——————————— ————————————总结:AI训练的本质
回顾一下我们讲的核心要点:
- AI是目标,机器学习是方法,深度学习是工具 - 三者是包含关系
- 监督学习需要标签,无监督学习自己找规律,强化学习通过奖惩学习 - 三种学习范式各有用途
- 损失函数量化误差,梯度下降优化参数 - 这是训练的核心机制
- 欠拟合和过拟合是两个极端,需要找到平衡点 - 模型调优的艺术
理解这些基础概念后,你就能更好地意识到GPT等大模型的能力边界:
- 它们的"智能"来自海量数据的统计规律
- 它们也会"过拟合"(重复训练数据)或"欠拟合"(在某些领域表现不佳)
- 它们本质上还是在做"模式匹配",而不是真正的推理
这也是为什么即使是最先进的大模型,在某些场景下也会"一本正经地胡说八道"(hallucination)——因为它只是在学习数据中的统计规律,并不真正"理解"知识。
下一步学习
如果你想继续深入:
- 实践派:动手用TensorFlow/PyTorch实现一个简单的神经网络
- 理论派:学习吴恩达的机器学习课程,掌握数学原理
- 应用派:直接上手Prompt Engineering,学会和大模型有效沟通
记住:AI不是魔法,是统计学+大规模计算。理解了原理,你就能更好地利用AI工具,而不是被它的"智能"表象迷惑。
这篇文章对你有帮助吗?欢迎留言分享你对AI的理解和疑问!